Анализ частоты букв в английском тексте
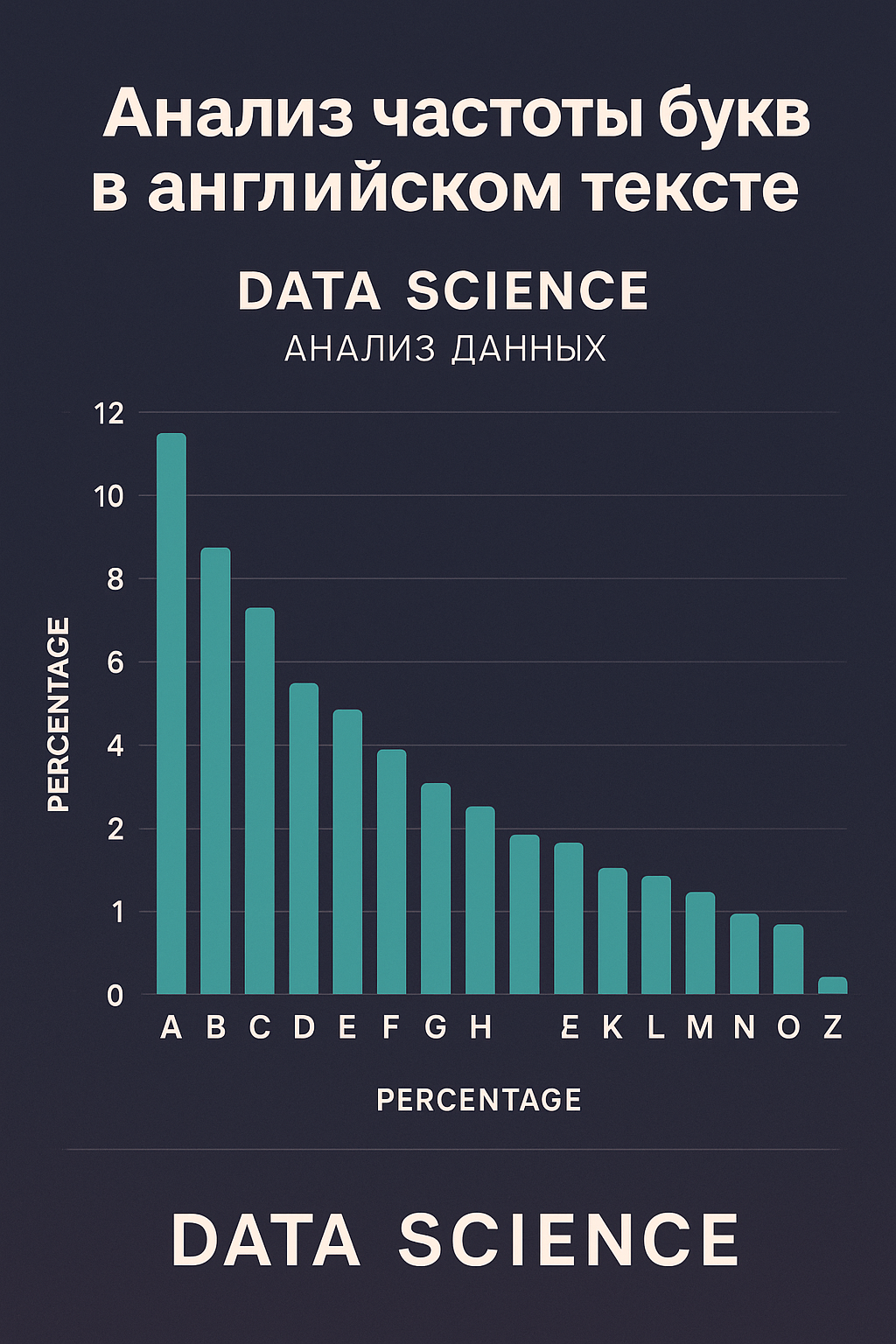
Проект посвящён анализу частоты использования букв в английском языке на примере знаменитого романа «Gadsby», написанного без самой популярной буквы E. Цель исследования — определить, какие буквы встречаются чаще всего, а какие — реже всего.
Основные этапы проекта:
📖 Обработка текста — удаление знаков препинания, приведение всех слов к нижнему регистру и подсчёт уникальных букв.
🔢 Подсчёт статистики — вычислена доля слов, содержащих каждую букву от A до Z, а также общее количество вхождений.
📊 Визуализация результатов — построена статистика в процентах, наглядно показывающая, какие буквы встречаются чаще.
🔍 Поиск редких букв — определена наименее употребимая буква в тексте.
Дополнительно проведено сравнение двух источников:
📂 тестового словаря и 📂 оригинального текста «Gadsby» с Google Диска.
Проект наглядно демонстрирует, как с помощью простой статистики можно исследовать особенности языка и создавать необычные лингвистические визуализации.
Дополнительные изображения:
