Распознавание рукописных цифр
Цель проекта — определить, какая из двух нейросетей лучше справляется с распознаванием рукописных цифр: более простая или более сложная. Для этого модели были обучены на тысячах изображений цифр и сравнивались по точности и скорости работы.
📌 Что сделано:
🔹 Подготовлены и обработаны тысячи изображений цифр
🔹 Созданы две нейросети разной сложности и проведено их сравнение
🔹 Проанализирована точность распознавания и скорость обучения
🔹 Построены наглядные графики для оценки прогресса моделей
📊 Итоги:
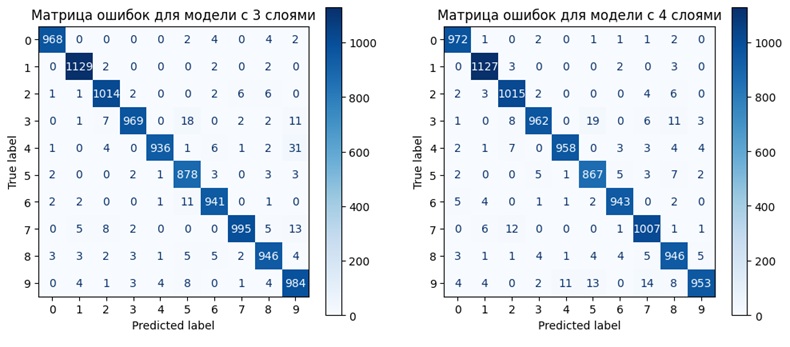
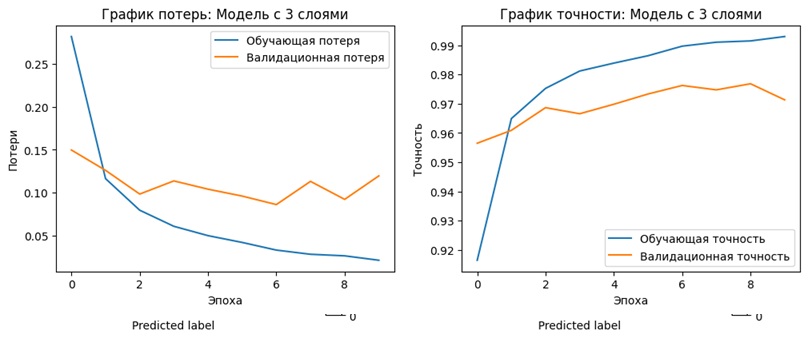
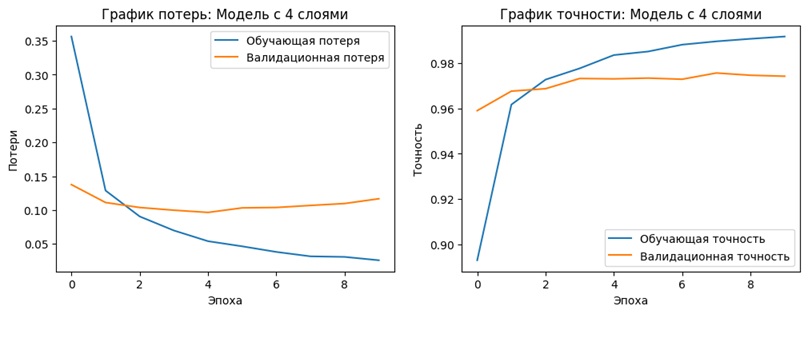
✅ Обе модели научились распознавать цифры с точностью выше 97%
✅ Простая модель показала чуть более высокую точность
✅ Сложная модель обучалась быстрее, но результаты почти совпали
💡 Вывод:
Обе нейросети хорошо справляются с задачей. Простая модель подходит, если важна максимальная точность, а сложная — если важна скорость обучения.
Дополнительные изображения: