Сравнение стратегий обучения на примере игр Acrobot и LunarLander
В этом проекте изучались два разных способа обучения искусственного агента, который играет в игру Acrobot. Один метод обучается, используя уже собранные данные, а другой — учится прямо во время игры, постепенно улучшая свою стратегию.
📌Что сделано:
🎮Реализованы два подхода к обучению агента для игры Acrobot
📈Проведено сравнение, как быстро и эффективно каждый метод учится играть
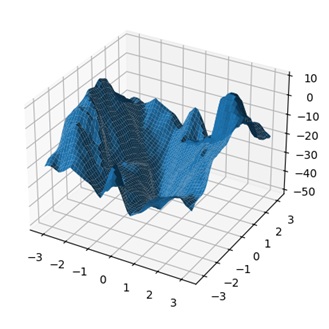
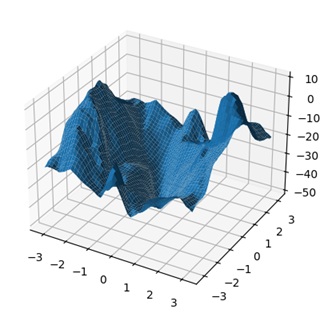
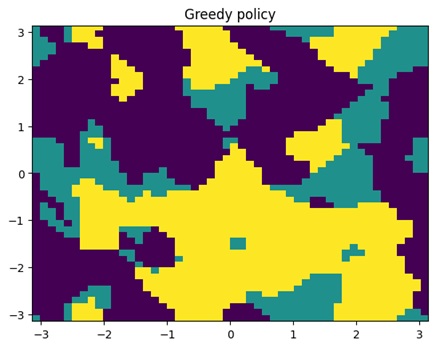
🔍Созданы графики, которые показывают, как меняется стратегия агента и его оценки действий
🎲Проведён анализ работы метода Монте-Карло на другой игре — LunarLander, где обучение оказалось менее стабильным
📊Результаты:
✅Метод с онлайн-обучением чаще даёт лучшие результаты при постоянном обновлении стратегии
✅Использование заранее собранных данных иногда уступает по эффективности
✅Метод Монте-Карло в сложных средах с большим количеством состояний показывает слабую сходимость
💡Вывод:
Для игр и задач с постоянным обновлением стратегии подход с онлайн-обучением оказывается предпочтительнее, а классические методы могут требовать доработки при работе с большими и сложными состояниями.
Дополнительные изображения: