Искусственный интеллект для игры в Pong

В проекте создан интеллектуальный агент, способный самостоятельно обучаться играть в классическую игру Pong с использованием метода Deep Q-Learning (DQN). Цель эксперимента — проверить, сможет ли агент освоить игру, используя только полносвязную нейронную сеть, без сверточных слоёв.
🔹 Суть проекта
• Агент наблюдает за игровым процессом через последовательность кадров
• Принимает решения о перемещении ракетки, чтобы отбивать мяч
• Постепенно учится повышать свой счёт, используя метод проб и ошибок
🔹 Особенности эксперимента
• Входные данные — кадры игры, преобразованные в градации серого
• Использована классическая DQN-архитектура с полносвязными слоями
• Применялась ε-жадная стратегия для исследования среды и обучения
🔹 Результаты проекта
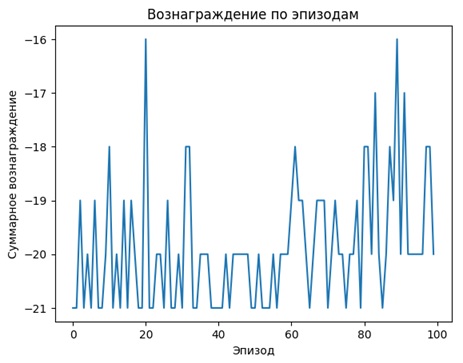
• 📈 Агент демонстрирует первые признаки понимания игры
• ⚠️ Обучение нестабильно и медленно без сверточных сетей
• 💡 Эксперимент наглядно показал важность пространственных признаков для успешного обучения
Дополнительные изображения: